Student Stories: From Theatrical Sound Designer to Financial Data Scientist was originally published on Springboard.
Meet Sam Fisher, a graduate of Springboard’s Data Science Career Track.
“I think of data science as an amalgam term,” says data scientist and machine learning engineer Sam Fisher. “When I hear the term, ‘data science,’ I think about how the fields of statistics and machine learning are mixing in ways that some traditionalists are probably even uncomfortable with. But they’re deeply entangled problems. ”
Sam speaks from experience. Since completing Springboard’s Data Science Career Track in 2018, his career has unfolded at the nexus of these two converging disciplines. We caught up with him to talk about pivoting into tech, how computers think, and life after Springboard.
What were you doing before Springboard?
I was a sound designer for a while after college. Once I started getting to work with some Broadway designers, I realized that this was just a field where it was really hard to make a living, even at the highest level. I wanted to make a pivot into something that still had a lot of the same creative facets as sound design, but I also had this yearning to do something that was a little more intellectual.
What drew you to tech?
When I was working at Berkeley Repertory Theater, I started a side project that was basically VR, but sound only. You could replicate, say, the whole experience of grabbing a bag of Doritos, ripping it open, and hearing it crunch as if it’s right there—without actually having a bag of Doritos. Instead, you just have a pair of headphones on.
To make those experiences happen, I designed a program that related hand motions to sounds. It involved a lot of coding. I decided that I wanted to pivot into tech, but I didn’t know what that looked like. Would I be a project manager? Would I be a programmer? I was interested in design, too.
So I went and got a job as a customer service person at a small tech company that sold software to Amazon merchants. What I ended up doing there really helped set the course into data science.
After working there for a bit, I realized that we weren’t doing much with all of the customer feedback that we were getting via emails. It’s a hard set of data to parse—you’d actually have to go and read it. That would take a lot of time. So we built this little product to deal with that. It was just a basic analytics-type effort, but it was valuable. That opened my eyes to the idea that there was probably a lot of unused data out there.
What pushed you to do a data science bootcamp?
I got a pretty interesting job at a music neuroscience company called Brain FM, which designs music to help people focus. I was mostly a composer, but I met an amazing person there who really pushed me in the data science direction. It’s because of him and his partner that I committed to doing a bootcamp.
Shortly after leaving Brain FM, I decided that I was going to become a data scientist. That was going to be my next job title, if it could be. I was very intimidated at the time because I felt like there was a big skills gap, but that year, I started Springboard’s Data Science Career Track.
What was your Data Science Career Track process like?
The bootcamp is designed so you can do it while you’re working full time. I was lucky enough to be in the position to take time off from work while I was doing it. I had committed six months to full-time learning and I was also taking some math courses at the same time.
I got a coworking desk and started coming into this building [the Little Rock Tech Park] every day. It was fantastic. I was stressed about the future quite often, but it was a time of a lot of curiosity.
At the very beginning of the course, you kind of go through this phase where everything is very mechanical. It’s like, here’s this specific library in Python, and with this library, you can manipulate data in this way. So you’re just zipping through this stuff like, “OK, I got it, I got it.”
My mentor said, “Focus on what you’re doing for your capstone projects because that’s where the real learning will take place.” And I think that was absolutely true. I spent quite a bit of time focusing on the capstone projects.
For my first capstone, I decided to work with text data. I still do a lot of work with text data, actually.
What is text data?
Basically, text data is data that consists of natural language. In other words, writing. The internet is covered in it. The issue is that computers don’t have a way of parsing natural language as intuitively as human beings do. Interpreting what a sentence means—that becomes a really hard math problem.
Formal languages like algebra are easy for the computer to interpret, but natural language is not a format that is native for quantitative analysis. It’s a distinction that’s made when thinking about language in the context of a computer. All of the statistical methods and machine learning methods that we have—for the most part, what they really, really like are matrices of numbers. So there’s this problem of turning natural language into matrices of numbers and doing that in a way that’s appropriate to the problem.
For my first capstone project, I had this data set that was all complaints that people made about their banks to the Consumer Financial Protection Bureau. The CFPB makes this data public, so I grabbed it.
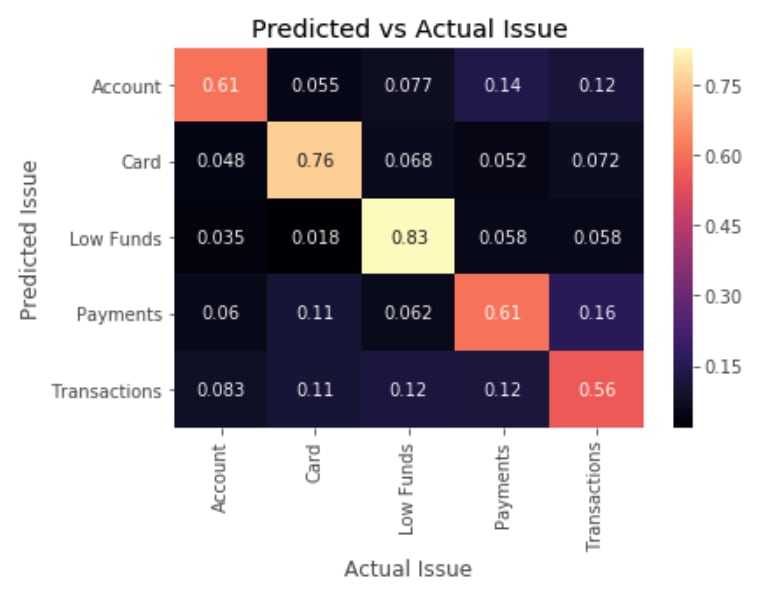
(This plot describes the model performance with a confusion matrix.)
These emails belonged in categories and had been labeled by humans. So, imagine these emails are coming in bins to different customer service agents who specialize in different areas. To solve the problem of routing them, you might want a program that can take the text of the email, put it in the appropriate bin, and send that to the right agent.
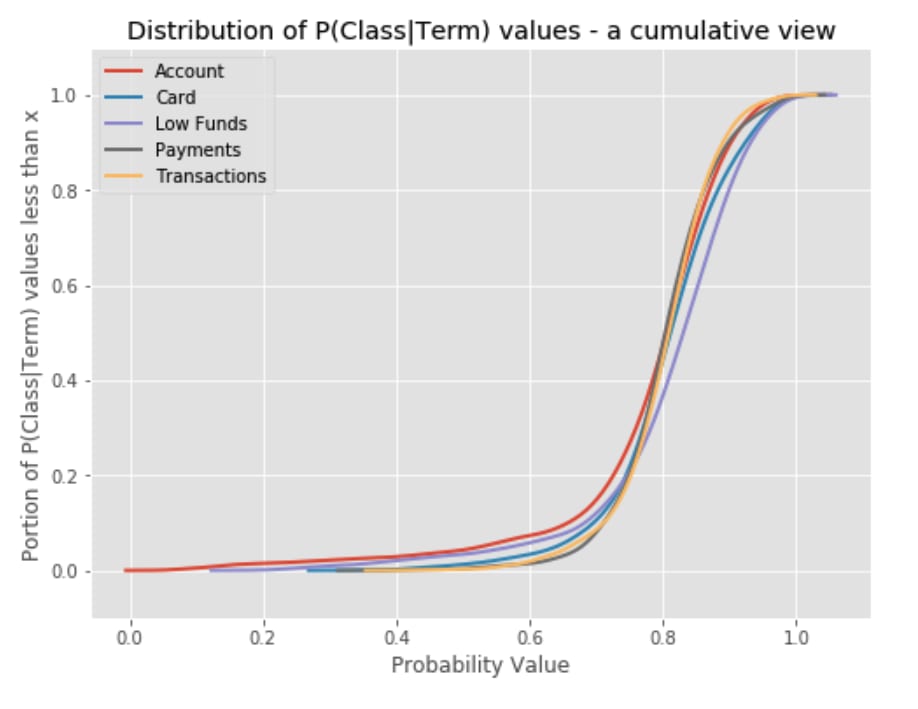
This plot shows the distribution of how strongly terms tended to be associated with a particular class. More technically, the probability that a document belongs to a class given that the term occurred in that document.
Is that a natural language processing problem?
100 percent. It’s also a classification problem. You have this text data, you need to get it into a numerical format, and then you need to apply a classifier to it that will distinguish which category it belongs in. So this is also a multiclass classification problem—these are common in relation to text data. I think there is probably a huge amount of economic activity purely around multiclass classifiers that have text data as their input.

Some of the terms that were used as features for the classifier.
What was your mentor’s role in relation to your project?
Evan had a degree in statistics and at the time was consulting on defense contracts through a company called Elder Research. His work was totally secret, but I do know that he had a lot of expertise around machine learning and was clearly spending a lot of time applying it. He was able to give a lot of advice about that.
Basically, I would try things and then bring them to our video call. I would tell Evan where I was getting stuck and he would suggest options I could try out to get unstuck. There are all kinds of models out there, right? But at this point, I’m someone who has no experience with these models. So I don’t know what would be reasonable to use, I don’t have those kinds of intuitions yet. Evan helped provide some of those insights.
When I was working on my first capstone, I spent a lot of time messing around and having ideas not work out. And that was productive. But my second capstone project, I had built up more intuition through trying things and experimenting.
Data science problems aren’t usually laid out in the real world as, “I would like a classification model for this data.” They’re more like, “I want to understand what these politicians are talking about on Twitter, and here are a million tweets.”
Learning how to frame problems, and having enough experience to figure out which methods make sense contextually, is really important. Those skills were more developed for me after the first capstone.
How did Springboard help you build those skills?
Springboard definitely teaches you how to do applied data science, how to take a specific problem and apply a model to it and see if that model is working well. Springboard is perfect in the sense that it helps you build intuition about what will work and what won’t from practical experiences. You’re trying different approaches to solve a real problem, and that’s really important.
Networking is also a big part of what’s taught. You learn to provide value upfront, so people know you’re good at what you do. Networking actually helped launch my career. I was in the tech park while doing this bootcamp, and the day that the bootcamp was finished, I had a job offer with a startup through the network I had established there.
What was the job?
It was a software engineering job, but it was data science-y. The company wanted to develop a product around voice, so at first, it was a lot of getting used to good software engineering practices. But that was tremendously helpful because now I build production machine learning systems, so the code has to be good. I built my first sort of production machine learning system at that job. It was an anomaly detection system.
After the company folded, I moved into freelance and started working with a lot of different people. One of the most interesting was this genomics company that was building a test to detect cancer earlier than any other known method, using blood samples. The model would look at the presence of mutations in the blood and spit out the probability of each type of cancer, and at what stage. It used this approach called Bayesian networks, which I had gotten really interested in from the anomaly detection problem.
I also did another project with them about choosing which blood samples to use for genomic sequencing. You want to choose samples that would result in the best data set for the machine learning algorithm to learn from when it tries to build the model to predict whether someone has cancer. The framing came down to, you want a sample that is well-balanced across all meaningful parameters. Age, gender, and ethnicity. Ethnic underrepresentation is a really common problem in medical trials.
LinkedIn says that you’ve just started a new job—can you tell us about it?
Yes. The company is a financial technology startup working on the problem of mitigating bias. Basically, you want to make sure that models aren’t giving unfair results when they’re making decisions like, “should you get a loan?”
This requires a method of doing machine learning that’s more interpretable, more explainable. Right now, people are frustrated about how neural networks and random forests, to a lesser extent, can’t explain or justify their decisions. These models rely on sets of weights and dense networks—kind of like the brain—that you have no idea how to interpret. So how can you scrutinize or audit them?
Models that decide whether you should get a loan or not certainly should be subject to scrutiny—so this company is working to generate models with interpretable rules. If the model is easy to understand and tweak, it’s possible to mitigate bias because you can actually change the way that it’s making decisions, retest it, and make sure it’s still accurate. If you try to make those kinds of tweaks with a neural network, you’re out of luck. You have to kind of go back to square one and try to get a better data set.
Do you have any advice for future Springboard students?
If you had another kind of career first, you might have some doubt around the idea that you can pivot into this highly quantitative and technical thing. But your natural capabilities and creativity and intelligence, all of that will transfer given enough time and practice. Stick to it.
Here at Springboard, not only do we pride ourselves on our students’ successes, but we genuinely believe that their dreams are what make up the foundation of our mission. Our alumni dream big—and they make big moves in stride. So we’re shining a light onto some of our favorite alumni stories: their journeys tell stories of accomplishment, grit, and determination against all kinds of odds.
Find more inspiring Springboard student success stories here.
The post Student Stories: From Theatrical Sound Designer to Financial Data Scientist appeared first on Springboard Blog.